College Publisher to WordPress conversion script is now open source
Alternate title for this post: Let the exodus continue. The Python conversion script CoPress used to migrate over 50 student publications to the glorious free and open source WordPress is now itself licensed under GPL version 2. It’s optimized for College Publisher 4 and College Publisher 5 databases, but will also work with most any database you can turn into a flat CSV file. You can fork it on Github or download the brand new 1.0 release.
Right off the bat, I’d like to say that the most awesome bit about the conversion script is its ease of use. Granted, you do have to run it on the command line and it does often throw mythical, unintelligible errors if your data is screwy, but it’s about 100 to 1,000 times easier than what Sean Blanda or Brian Schlansky had to go through. Furthermore, it spits out WordPress eXtended RSS files that WordPress imports natively. Depending on the size of your archives, you could even do the entire migration in less than a half hour.
There are detailed instructions in the README I encourage you to read thoroughly but, in screenshots, here’s how you’d migrate your site.
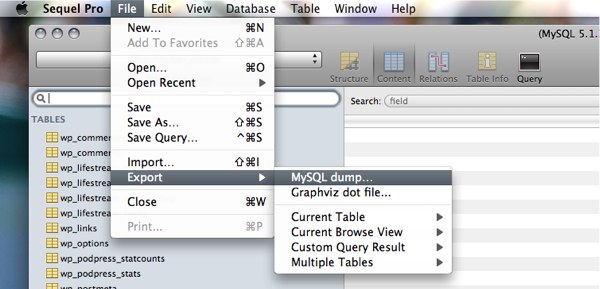
Backup your database using Sequel Pro. This is a critically important step, as you’ll definitely want a clean version to revert to if the import goes awry.
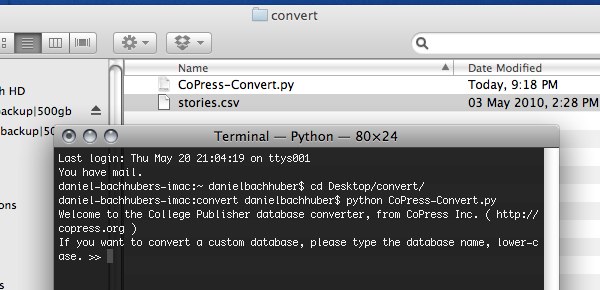
Place the conversion script and your archives in a folder you can access from the command line. Both College Publisher 4 and College Publisher 5 migrants should receive an articles file that will need to be renamed “stories.csv.” Publications migrating from the former will have all of their image references stored in a file that will need to be renamed “media.csv.” Navigate to that directory from your terminal prompt and run “python CoPress-Convert.py.”
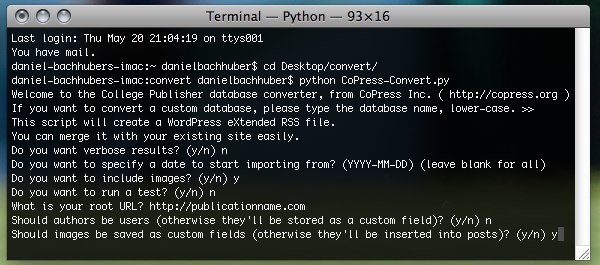
Once the script is running, you’ll be asked a series of questions to configure the conversion process. Most options are self-explanatory, and all are explained fully in the README file packaged with the script. The most important thing I’d like to note in this post is that, unless you have less than 500 authors in your archives, I’d highly, highly recommend importing your authors as custom fields instead of users. WordPress is not optimized to add a large number of new users through its import process. We learned this the hard way migrating CM Life’s database last summer.
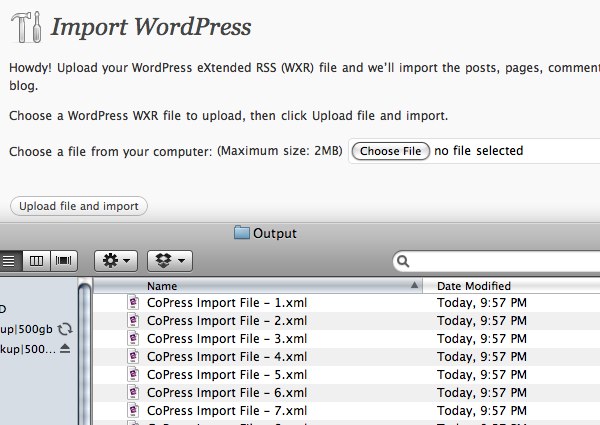
When the script is done, you’ll have a series of WordPress eXtended RSS files you can easily upload into WordPress.
Mad props go to Miles Skorpen for the long hours he spent on the conversion script, and to Albert Sun, Will Davis, and Max Cutler for their later contributions.
Feel free to send along any suggestions for improvement, bugs, fixes or general comments. I intend to maintain it for the indefinite future, it’s good Python practice when everything else I’m working on is PHP, but code contributions are always welcome. There is a short list of upgrades under consideration in the top of the script.